
 지혜의 개발공부로그
지혜의 개발공부로그
운영체제 역사(Operating System History)
24 Nov 2019 | OS operating system개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
경성대학교 양희재 교수님 수업 영상을 듣고 정리하였습니다.
컴퓨터의 역사!
1. No operating System
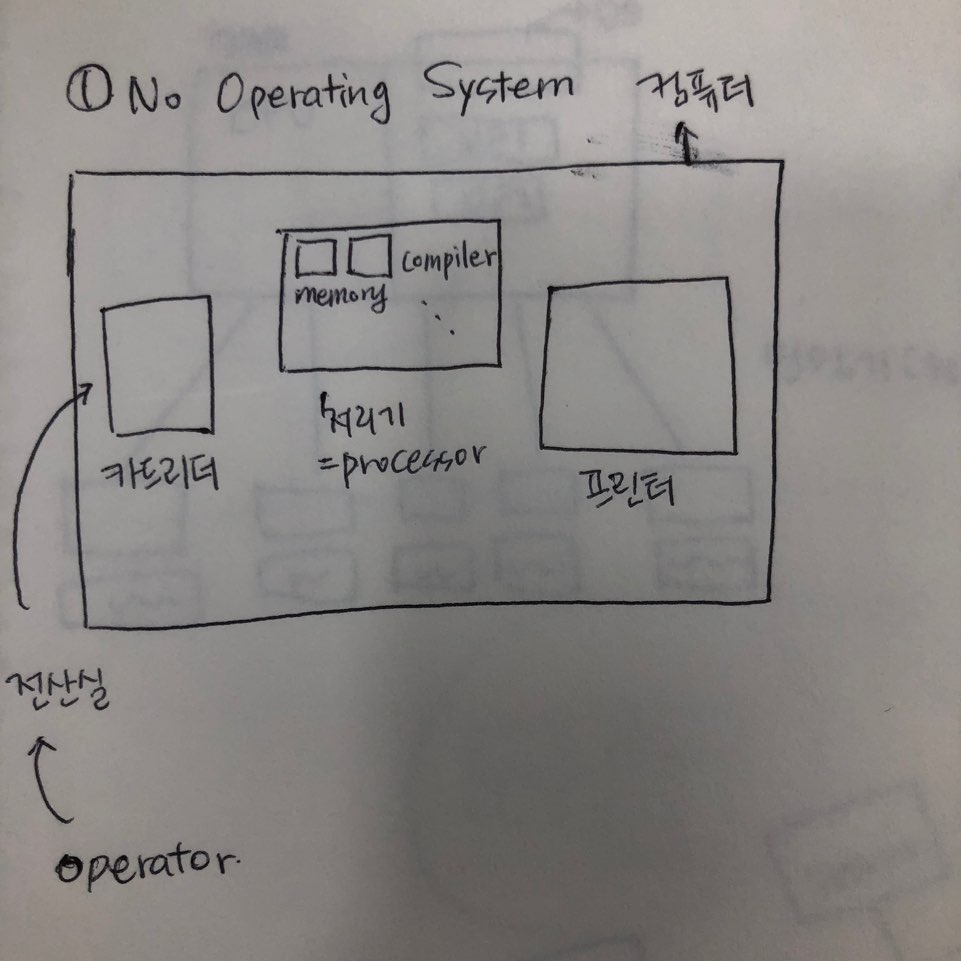
처음 컴퓨터가 만들어진 때는 세계 2차대전 중 1940년대 말 즈음이다. 컴퓨터의 발전과 함꼐 하드웨어의 발전도 이루어졌고, 그에 따라 운영체제의 기술 또한 발전되었다. 제일 처음 발명된 컴퓨터의 크기는 너무 컸기 때문에 책상위에 올려둘 수도 없었고 아예 한 건물안에 컴퓨터 하나가 들어가있는 모습이었다.
그 건물에서 제일 큰 비중을 차지하는 것은 입력장치(카드리더)가 있는데, 이 카드리더에는 여러가지는 OCR에 적힌 내용을 읽어 처리기에 보내고 처리기에서 컴파일러 한 내용을 그대로 프린트(io)에 찍어보낸다.
이때의 컴퓨터는 일반인들은 사용 하지 못했고, 컴퓨터를 작동시키는 오퍼레이터라는 직업이 따로 있었다. 따라서 오퍼레이터(프로그래머)가 종이에 연필로 프로그램을 적어 전산실에 넘기면 전산실에서는 연필로 작성된 코드들을 OCR 카드에 구멍을 뚫어서 그 구멍을 통해 카드리더가 코드를 파악했다. 그럼 이 내용들이 처리기의 메모리에 적재되고 즉, 메모리가 프로세서에 올라가게되면 카드리더에 있던 파일은 삭제되고 이 메모리를 읽기 위한 컴파일러가 카드리더에 올라가 처리기로 옮겨지면서 처리기에는 메모리와 컴파일러가 올라가 있게 된다.
이 컴파일러는 이제 이 메모리를 번역하기 위해 기계어가 나오고 처리기는 기계어를 실행한다. 이때는 모니터가 없으니 그 결과는 프린터에 찍힌다.
그래서 처음의 컴퓨터에는 별도의 운영체제가 존재하지 않던 No operating system이었으며, 기술이 발전과 함께 컴퓨터 스스로 할 수 있는 운영체제가 만들어지기 시작했다.
2. Batch processing System
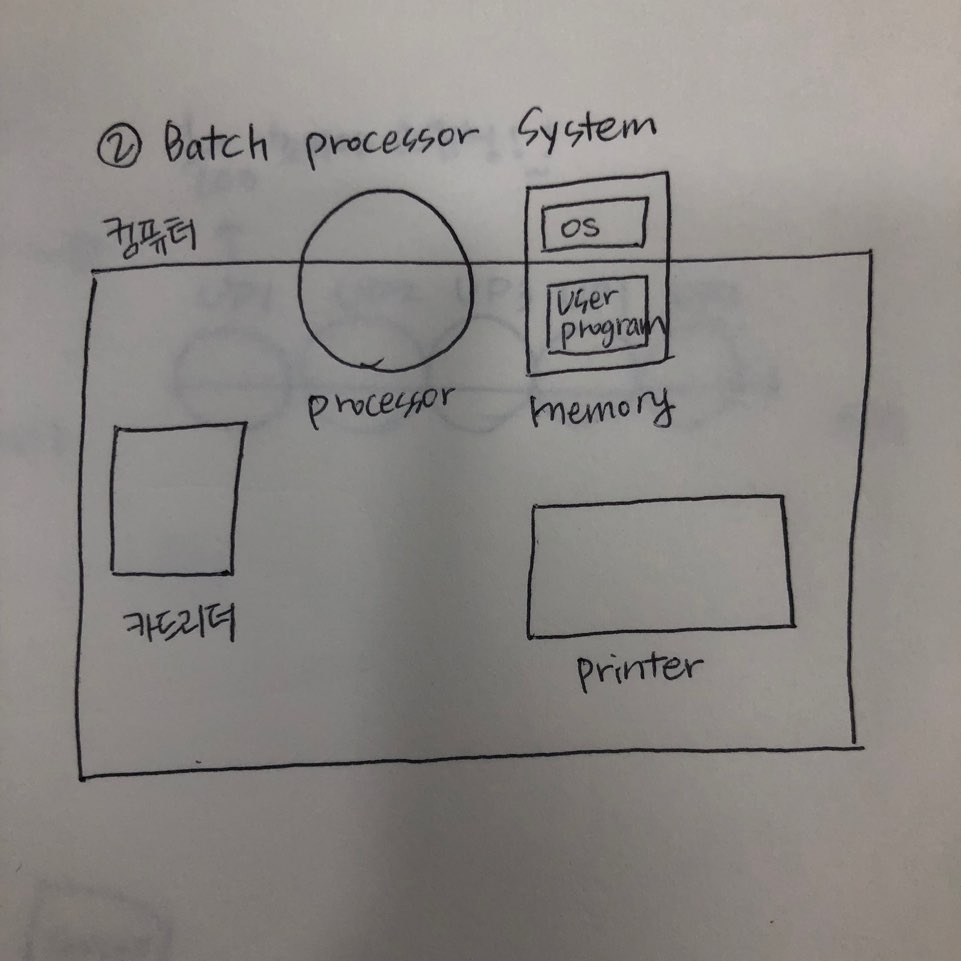
Batch: 꾸러미, 묶어서 프로세스를 처리를 한다 (일괄처리)
과거에 오퍼레이터가 했던 일련의 동작들을 이제는 메모리에 프로그램들을 넣어 컴파일 > 링크 > 로드하도록 하는, 즉 프로그램들을 메모리에 넣는 것 을 Batch processing system(일괄처리 시스템)이라고 한다.
이 메모리 안에 들어있는 작은 프로그램을 레지던트 모니터(resident monitor)라고 부른다. 메모리에 상주함으로써 일괄적인 일들을 한다고 해서 batch라는 단어를 붙였고 이를 최초의 운영체제로 본다. 그 후에 기술이 발전되어 메인 메모리 외에도 하드디스크(기억용량이 크고 속도도 빠름)도 만들어지고 그리고 이때의 메인메모리는 반도체 메모리가 아닌 진공관 메모리여서 이후 트랜지스터 등등이 생기면서 메모리가 굉장히 커지고, 프로세스 속도도 빨라지게 된다.
즉, 하드웨어 기술이 발전되며 os에도 변화 또한 굉장히 커졌다.
3. Multiprogramming System
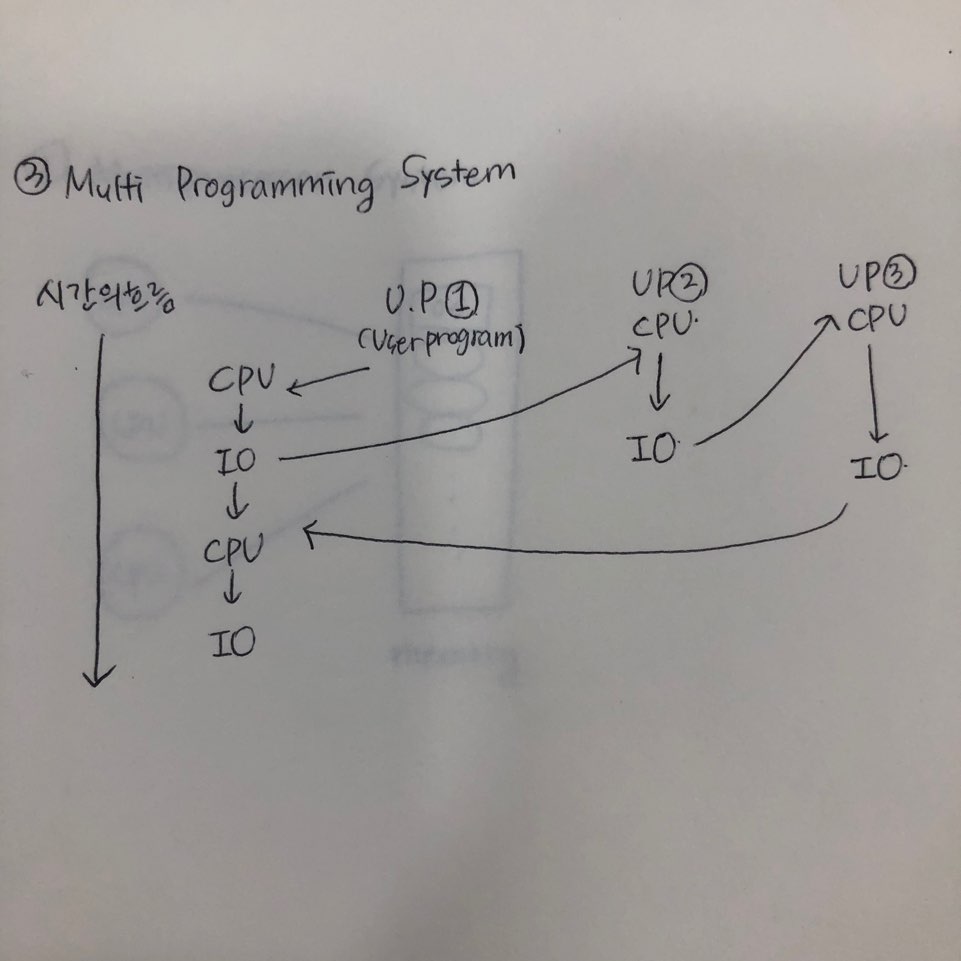
os(운영체제)의 변화중에서도 가장 큰 변화인 멀티 프로그래밍(다중 프로그래밍)이다.
옛날에는 컴퓨터가 정말 비쌌고, 미국에도 많아야 5개가 안됐다.(우리나라에는 없었고) 그래서 사람들이 생각해보면 batch processing system도 좋았지만 단점도 존재했다.
- 컴퓨터를 생각해보면 기본적으로 메모리에는 os와 유저 프로그램이 들어있다.
- 다양한 유저 프로그램중에는 메모리에 하나만 올라갈 수 있었다.
- 동시에 여러 프로그램이 메모리에 올라갈 수 없었다.
우리가 프로그램을 통해 어떤 연산을 할때에는 cpu를 사용하는데, 프린트를 통해 화면에 무언가를 입/출력할 때(io)에는 cpu를 사용하지 못한다. 즉 우리는 다양한 프로그램을 사용하고(cpu를 사용하고) 입/출력(io)를 하고싶은데 이를 동시에 진행하기가 어려운 것이다.
즉 시간경과에 따라서 cpu->io->cpu->io 이렇게 도는 것을 볼 수 있다.
더 나아가 batch processing system은 유저 프로그램이 하나 있었는데 처음 프로그램을 실행할때에는 cpu가 동작하지만, io가 실행할때에는 cpu는 io가 끝날때까지는 할일이 없다. 그래서 이때 cpu가 아무일도 안하고 놀게 되는데 이를 idle이라고 한다. (idle은 아무일도 안하고 빙빙 돌고있다는 뜻)
컴퓨터는 굉장히 비싼 자원이고 cpu의 연산속도는 무척 빠르지만 io의 속도는 느리고, 그렇다는 것은 io가 진행될때에는 cpu가 계속 놀고있게 되니 이를 해결할 방법을 마련한 것이 Multiprogramming system(다중 프로그래밍)이다.
메모리에 여러개의 프로그램을 돌리자!
cpu가 idle하지 않고 다른 프로그램(다른 유저 프로그램)으로 내려가게 된다.
그래서 원래 진행하고 있던 프로그램에서 io를 진행하고 있다고 하더라도 cpu는 계속해서 다른 프로그램으로 옮겨감으로써 일을 계속 하게될 수 있게된다. cpu는 되게 비싼 자원이기 때문에 이런식을 통해 메모리의 작업/프로그램을 수행하도록 한다. 어느 순간에도 cpu가 idle하지 않도록!
이 방식을 통해 idle 타임을 대폭 줄이고 cpu의 사용률이 올려버린다. 즉, 메인 메모리에 여러개의 프로그램을 올리는 것을 다중 프로그래밍 시스템이라고 한다.(프로그램이 여러개)
멀티 프로세싱 시스템을 채택하게 되면서 이제 우리는 단순하게 메모리에 프로그램을 여러개 올리는것만으로 끝나는게 아니라, 여러개의 생각해봐야 할 이슈가 생겼다.
- CPU scheduling: 메인 메모리에 프로그램이 여러개 있으면 어떤 순서대로 cpu를 사용할 것인가?
- 성능을 향상 시켜야 하니까, 성능이 더 좋은 방식으로!
- 메모리 관리: 이제는 메모리의 유저프로그램들이 많아졌으니까, 유저 프로그램들을 각각 어디에 배치하는것이 좋을까?
- 프로그램이 종료된다면 이 새로운 프로그램을 넣으려고 하면 비어있는 곳? 아니면 그 다음?
- 보호: 다른 프로그램 영역까지 침범할 수 있으니 이를 막아햐 하잖아.
4. Time Sharing System
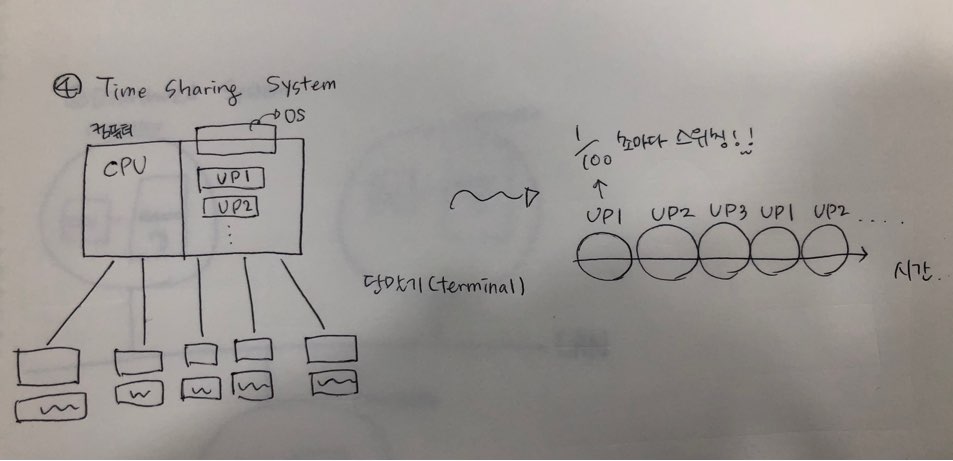
더 나아가, 60년대 후반 70년대로 오면서 모니터, 키보드가 생겨나게 되면서 컴퓨터와 사용자간의 interactive가 가능해졌다.
옛날에는 컴퓨터 한대의 값이 너무 비싸서 한사람이 쓰지 못하고, 하나의 컴퓨터에 단말기(terminal)를 연결해 각각의 컴퓨터와 키보드가 연결해 사용했다. 근데 이때의 컴퓨터 모양은 지금과 비슷해보이지만 조금 다르게 생겼다. 지금은 본체가 있어서 그 본체에 cpu와 메모리가 있지만 과거에는 그냥 단순히 모니터와 키보드로만 이루어진 입출력 장치에 불과했다.
그래서 옛날에는 하나의 컴퓨터에 수많은 단말기를 달아서 사용했다.
컴퓨터를 여러명이 사용하려다 보니, 처음 유저프로그램1을 실행을 하면 이 사이 유저2,3은 아무것도 실행하지 못한다.(cpu가 하나이기 때문에..) 하나의 컴퓨터를 여러명이 동시에 사용하려면 위에서 이야기했던 multiprocessor system을 사용하기는 힘들다.
이를 해결하기 위해서는 프로그램이 3개라고 한다면 1분에 1/100초 마다 cpu가 스위칭을 해줘야한다.
즉, io를 만날때마다 스위칭해주는게 아니라 아주 짧은 시간동안 계속해서 움직이게 한다. 그러면 유저가 3명이고 1/100초마다 스위칭이 된다면 한 사람마다 1초에 총 33번의 cpu가 할당되는 기회를 얻는다. 이렇게 되면 cpu는 워낙 빠르니까 유저는 혼자 컴퓨터를 사용하는 것처럼 느껴지게 된다.
이를 TSS(Time Sharing System)시공유 시스템이라고 한다. 일정 시간이 지나면 강제절환(Switching)하고 대화형 시스템이 가능해진다.(명령내리고 응답받고..)
- 사용자가 여러명인데 다른 사용자에게 메시지를 보낼 수도 있음 (ex.카카오톡..)
- 하나의 컴퓨터를 여러명이 쓰다보니까 서로 데이터를 주고받는것이 가능해짐
- 프로세스간 통신이 가능해짐
- 유저 1,2,3이 거의 동시에 실행되다 보니까 누가 앞서도 뒤서야하는지 알아봐야함(동기의 개념이 대두됨)
동기란?
싱크로나이즈 > 여러명이 짝을 이뤄 움직이는것
즉, 프로그램이 여러개 동시에 있다보니 누가 순서를 앞서도 뒤서야하는지를 해결해야하고, 이를 동기라고 한다.
늘어나는 유저상황에서 적은 메모리로는 어떻게 이를 유지할 수 있을까?
- 새로운 기술이 나타남: 하드디스크가 보편화됨
- 하드디스크의 일부를 메인 메모리인양 사용
- 사실은 메인메모리가 아닌데, 하드디스크가 메인메모리처럼 보이게 함
- 그래서 cpu가 보기에는 메인메모리가 크게 보이는것 > 가상메모리처럼..
운영체제는 성능향상을 시킨다고 했는데 바로 위에 저런 기능들을 통해서 성능향상을 시킬 수 있게 된것이다.
그래서 결론적으로 지금 우리가 사용하는 대부분의 운영체제는 TSS이다! 그 이후로는 os의 특별한 발전은 없었는데, 왜냐하면 거의 완성이 되었기 때문이다.
단일 cpu를 사용한 가장 최신의 운영체제가 되었고 unix, linux도 마찬가지고 mac, 윈도우 모든 TSS를 사용하고 있다.
os 기술의 천이
가장 강력한 컴퓨터는 무엇인가?
- supercomputer: 가장 최강의 컴퓨터, 메모리용량도 크고 cpu도 빠르고 보조기억장치도 엄청나다.
- mainframe: 한 컴퓨터에 수백대의 단말기를 달아 사용(수백명의 사람들이 동시에 사용하는 것)
- minicomputer: 단말기가 수십대
- micro: 작으면 한명정도..
이건 옛날 구별이고 이제는
- supercomputer
- server
- work station
- PC
- handheld: 손에 들고다니는 컴퓨터 / 노트북, 태플릿, 스마트폰..
- embedded: 어디에 파묻혀있다. 즉, 내장되어져있다.
- 컴퓨터가 어디에 포함되어있다. 자동차안의 컴퓨터(엔진제어..), 전기밥솥 안의 cpu, 냉장고, 세탁기..
- 우리 눈에는 안보이지만, 세탁기도 지능화되어야하니까 컴퓨터가 들어잇다.
이 모든 컴퓨터에는 모두 운영체제가 들어가 있다. 운영체제가 없으면 우리가 그것을 사용할 수가 없다. 그래서 아무리 간단해 보이는 컴퓨터라고 하더라도 모두 운영체제가 들어있다.








