서버는 사용자의 요청(request)을 해석하여 데이터를 가공 후 생성된 웹 페이지를 보냄
사용자는 상황, 시간, 요청 등에 따라 달라지는 웹 페이지를 보게 됨
인터넷을 사용하다보면, 크게 웹페이지는 정적 웹페이지와 동적 웹페이지로 나뉜다. 정적 웹페이지는 컴퓨터에서 저장된 텍스트 파일을 메모장을 통해 열어보듯 저장된 그대로를 보는것이며, 동적 웹페이지는 그런 내용들이 다른 변수들에 의해 변경되어 보여진다. 가장 큰 차이는 사용자가 받아보는 웹 페이지가 동적으로 변하는 가 아닌가 에 있다.
우리가 보는 대부분의 웹페이지는 동적 웹페이지라고 할 수 있다. 뉴스사이트의 뉴스를 보거나, 포털에서 웹툰을 보거나 하는 행위는 사용자의 요청에 따라 원하는 페이지를 동적으로 생성하여 보내주는 것이다. 만약 정적인 웹 페이지로만 구성하여 홈페이지를 만들게 되면, 새로 업데이트를 하거나 제거를 할때마다 정적 웹 페이지를 제작해줘야하는데 이를 동적 웹페이지로 구축하게 되면 해당하는 스크립트만 작성하고 자동으로 페이지가 생성되게만 해주면 사이트의 관리 비용이 절감할 수 있게 된다.
사용자 입장에서는 사실 서버에서 처리된 웹 페이지를 전달받기 때문에 정적이든 동적이든 크게 상관이 있지않다. 결국 웹페이지는 HTML로 이루어진 웹 페이지 이기 때문이다.
정적 웹 페이지의 장/단점
정적 웹 페이지
장점
빠르다: 요청에 대한 파일만 전송하면 되기 때문에 추가적인 작업이 없다.
비용이 적다: 마찬가지로 웹 서버만 구축하면 된다.
단점
서비스가 한정적이다: 저장된 정보만 보여줄 수 있다.
관리가 힘들다: 추가/수정/삭제의 작업 모두 수동으로 이루어져야 한다.
동적 웹 페이지
장점
서비스가 다양하다: 다양한 정보를 조합하여 동적으로 생성하여 제공이 가능하다
관리가 쉽다: 웹 사이트 구조에 따라서 추가/수정/삭제 등의 작업이 용이하다.
단점
상대적으로 느리다: 사용자에게 웹 페이지를 전달하기 전에 처리하는 작업이 필요하다.
추가 비용이 든다: 웹 서버외에 추가적으로 처리를 위한 어플리케이션 서버가 필요하다.
동적 웹 사이트는 정적 웹 사이트와는 달리 서버 내부에서 추가적인 작업이 필요하기 때문에 서버 내부에 그런 작업들을 처리하기 위한 모듈같은 것이 필요하다. 따라서 서버를 구성할 때 필요한 모듈들을 설치해야하고, 웹 호스팅을 이용할 때에도 해당 모듈을 제공하는 서비스를 선택해야한다.
이런 모듈들은 서버의 자원(CPU, 메모리 등)을 이용하기 때문에 비용이 들기도하며, 이런 모듈들을 이용해 동적 웹페이지를 생성한다는 것 자체가 바로 전송이 가능한 정적인 웹 페이지에 비해 느린것도 사실이다. 그러나 웹 사이트 구축과 운영/관리 측면에서 봤을때, 구조화된 웹사이트 구축과 관리의 용이성 때문에 전체적인 비용이 절감되는것도 사실이다.
정적인 웹 페이지는 각각 독립되어 있기 때문에 같은 코드가 포함된다하더라도 각각 따로 저장되어야 하지만, 동적 웹 페이지는 중복 코드를 하나의 파일로 만들어 스크립트 불러오기가 가능하다. 따라서 구조화된 웹 사이트를 구축할 수 있는 장점이 있다.
이러한 특징으로 정적 웹페이지보다 동적 웹 페이지를 더 많이 사용하긴 하지만, 정적 웹사이트가 아예 사용되지 않는 것도 아니다. 정적 웹 페이지는 자주 변경되지 않는 페이지(about 등)에 대부분 사용되어 만들어진다. ㄸ라서 웹 사이트의 성격에 맞게 각각 페이지 특성에 맞게 적절히 섞어 사용하는것이 가장 좋다.
프로그래머는 소스코드를 작성하는데, 이를 프로그래밍이라고도 한다. 즉, 소스코드는 개발자가 사용하는 언어에 따른 명령어들의 조합이라고 볼 수 있지만 명령어 실행을 위해서는 기계어 즉, 저레벨 언어로 쓰여져야만 하드웨어 제어가 가능하다.
저레벨 언어(low-level language)
기계어, 어셈블리어를 의미
고레벨언어보다 하드웨어와 더 밀접한 언어이다.
고레벨 언어(high-level language)
프로그래밍에 좀 더 특화된 언어이다.
기계어보다 좀 더 인간의 언어에 가깝다.
저레벨 언어보다 읽기 쉬우며, 읽기 뿐만 아니라 쓰기, 유지보수에도 용이하다.
즉, 프로그램을 생산하기 수월하다
그러나 고레벨 언어는 기계어로 변환하기 위한 인터프리터나 컴파일러가 필수적으로 요구된다.
즉, 컴파일러는 고레벨 언어를 저레벨 언어로 변경하기 위해 필요한 장치 또는 도구라고 볼 수 있다.
프로그래밍 자체가 하드웨어를 제어하기 위해 탄생한 것으로 볼 수 있고 이를 조작하기 위해서는 기계어로 작성해야하지만, 기계어로는 프로그래밍을 작성하기 매우 까다롭기 때문에 인간에게 더 친숙한 고레벨 언어가 탄생하였고 이 고레벨 언어로 작성한 프로그램이 작동하기 위해서는 컴파일러가 필요한것이다.
해당 프로그램이 시작되면 main함수가 먼저 시작할것이다. main함수의 MyThread가 실행되면서 while문의 무한루프가 돌면서 B가 계속해서 찍혀나갈 것이고 그와 동시에 main함수의 while문이 무한루프를 돌면서 A를 계속해서 찍어낼 것이다. 컴파일해보면 A와 B가 섞여서 찍힐 것이다.
프로세스 동기화(Process Synchronization)
더 정확한 표현은 Thread Synchronization이다. 서로간 영향을 주고받는 데이터들간에 데이터의 일관성이 유지될 수 있도록 해주는 것이 동기화이다.
보통 컴퓨터 메모리 안의 프로세스들은 독립적이지 않고 협조하는 관계이다. 즉, 다른 프로세스에게 영향을 주거나 영향을 받는다. 대부분 공통된 자원(메인메모리)을 서로 접근하려고 하다보니 그런것이다. 하나의 메인메모리에 프로세스들이 많으니 어떤 방식으로든 영향을 주고받으니 그럴수록 프로세스 동기화의 개념이 중요해지고 있다.
Processes
Independent vs Cooperating
Cooperating process: one that can affect or be affected by other processes executed in the system(그 시스템 내에서 실행되고 있는 다른 프로세스에 대해서 프로세스 간 영향을 주든지 영향을 받든지하는 프로세스)
프로세스 간 통신: 전자우편, 파일 전송(서로 공유하며 데이터 통신을 함)
프로세스간 자원 공유: 메모리 상의 자료들, 데이터베이스 등(데이터를 공유하기에 서로에게 영향을 줌)
명절 기자표 예약, 대학 온라인 수강신청, 실시간 주식거래
Process Synchronization
Concurrent access to shared data may result in data inconsistency
Orderly execution of cooperating processes so that data consistency is maintained
-> 공유 데이터에 동시에 접근하면 데이터의 비일관성을 초래한다.
-> 서로간 영향을 주고받는 데이터들간에 데이터의 일관성이 유지될 수 있도록 해주는 것이 동기화이다.
시간지연에도 불구하고 결과는 바르게 나와야하는데, 이를 해결해야하는 것을 동기화라고 한다.
-> context switching이 중간에 일어나게 되면 이상한 결과를 초래할 수 있다.
-> 공통변수(common variable, balance)에 대한 동시 업데이트(concurrent update)로 인해 발생!
(즉, 하이레벨 랭귀지는 한줄이지만 로우레벨은 여러줄인데 업데이트 도중에 스위칭이 발생)
-> 해결: 공통변수에 대해 한번에 한 쓰레드만 업데이트 하도록한다! 임계구역 문제 = atomic하게!
임계구역 문제(Critical-Section Problem)
Critical section(임계구간, 치명적인 구간): 이 구간에서 아주 치명적인 오류가 발생할 수 있다.
A system consisting of multiple threads.
Each thread has a segment of code, called critical section, in which the thread may be changing common variables, updating a table, writing a file, and so on
여러개의 쓰레드로 구성된 시스템에서 각각의 쓰레드는 어떤 코드의 영역을 가지고 있는데, 그 코드의 영역을 임계구역이라고 한다. 이 임계구역이 되기 위해서는 여러 쓰레드들이 공통의 변수, 테이블, 파일들을 바꾸는 부분 코드를 임계구역이라고 한다.
Solution (3개가 모두다 만족되어야 한다.)
Mutual exclusive(상호배타): 오류가 일어나지 않으려면 공통 변수에 대한 업데이트는 오직 한 쓰레드만 들어가 있을 때 진행되어야 한다. 즉 Parent가 critical section에 들어가면 그 순간에는 Child가 critical section에 들어가면 안된다.
Progress(진행): 진입 결정은 유한 시간 내에 일어나야 한다. 즉 critical section에 누가 들어갈 것인지를 결정하는 것은 유한 시간 내에 일어나야 한다.
Bounded waiting(유한대기): 어느 쓰레드라도 유한 시간 내에 일어나야 한다. 기다리는 시간의 한계가 들어가 있다는 것으로 내가 기다리고 있다면 유한 시간 내에 critical section 안으로 들어갈 수 있다.
프로세스/쓰레드 동기화
임계구역 문제 해결
프로세스 실행 순서 제어(원하는대로)
Busy wait 등 비효율성 제거
프로세스 관리에서 중요한 것은 결국 프로세스/쓰레드의 동기화이다. 틀린답이 나오지 않도록 os에서 임계구역 문제를 해결해줘야 한다. 그리고 프로세스/쓰레드의 순서를 임의로 제어할 수 있어야 한다.
개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
경성대학교 양희재 교수님 수업 영상을 듣고 정리하였습니다.
CPU Scheduling
Ready Queue에서 프로세스들이 CPU의 서비스를 받기 위해 기다리는데, 현재 CPU에서 하고 있는 작업이 끝나게되면 어느 프로세스를 가져올지 결정하는 것
Preemptive vs Non-Preemptive (선점 vs 비선점)
Preemptive: CPU가 어떤 프로세스를 막 실행하고 있는데, 아직 끝나지도 않았고 IO를 만나지도 않았음에도 강제로 쫓아내고 새로운게 들어갈 수 있게하는 스케줄링 방식
Non-Preemptive: 이미 한 프로세스가 진행중이면 절대 스케줄링이 일어나지 않는 것
Scheduling criteria(스케줄링 척도)
CPU Utilization(CPU 이용률, %): CPU가 얼마나 놀지 않고 일하는가?
Throughput(처리율, Jobs/ms): 시간당 몇개의 작업을 처리하는가?
Turnaround time(반환시간, m/s): 작업이 들어온 시간부터 끝날때까지의 시간
Waiting time(대기시간, m/s): cpu 서비스를 받기 위해 얼마나 기다렸는가?
Response time(응답시간): 처음 응답이 나올때까지의 시간, interactive computer에서 중요
CPU Scheduling Algorithm
First-Come, First-Served(FCFS): 먼저 온놈을 먼저 작업한다.
Shortest-Job_First(SJF): 작업시간이 짧은 놈을 먼저 작업한다.
Shortest Remaining-Time-First
Priority: 우선순위가 높은 놈을 먼저 작업한다.
Round-Robin(RR): 빙빙 돌면서 순서대로 작업한다.
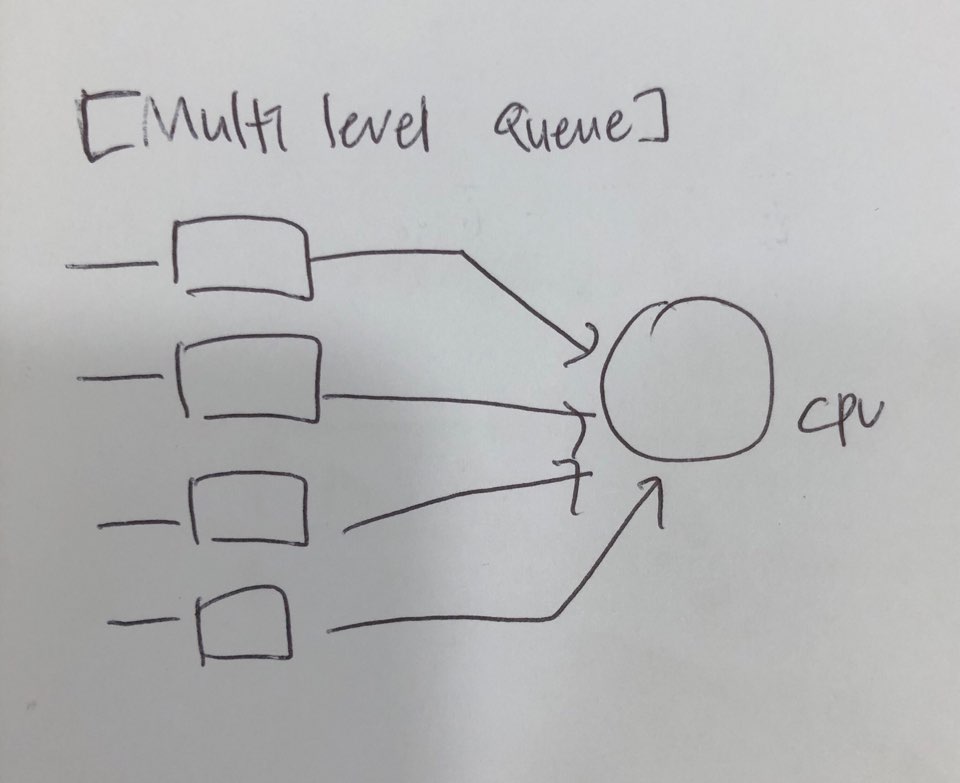
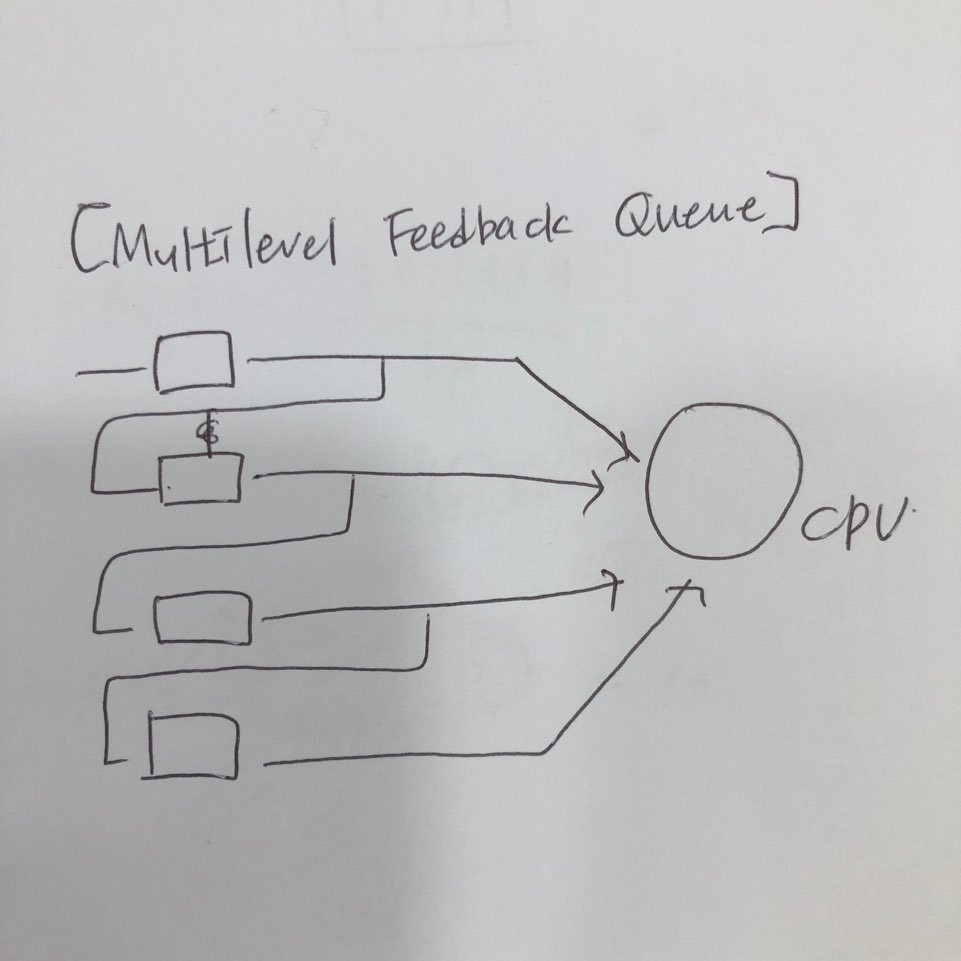
Multilevel Queue : Queue를 여러개 둔다.
Multilevel Feedback Queue
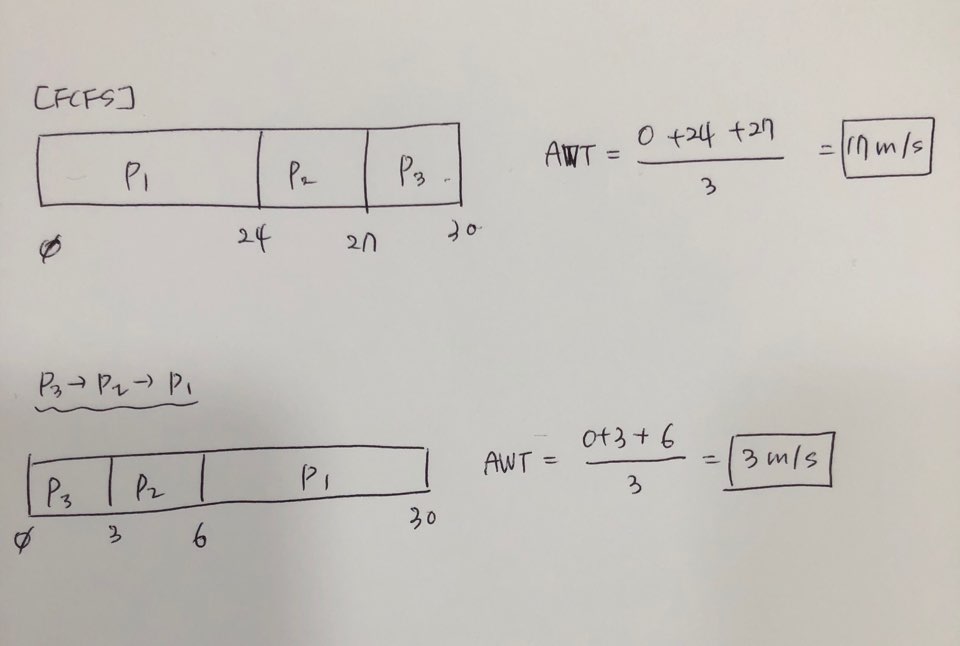
First-Come, First-Served(FCFS)
simple & fair: 먼저 온 놈을 먼저 작업한다. 제일 간단하고 공평한 방법이다. 그러나 정말 좋은 방법인가?
꼭 좋은 성능을 나타내는 것은 아니다.
example: Find Average Waiting Time
AWT = (0+24+27)/3 = 17 msec cf.3 msec!
3개의 프로세스가 거의 동시에 Ready Queue에 도착했다고 해보자.
Gantt Chart
Process
Burst Time(CPU 이용시간)
P1
24
P2
3
P3
3
Convoy Effect(호위효과): cpu 실행시간을 많이 쓰는애가 딱 앞에 있으면 나머지 애들이 뒤를 따라다니며 기다리고 있는 모습-> FCFS 의 단점
Non-Preemptive Scheduling: p1이 끝날때까지 나머지는 못들어감.
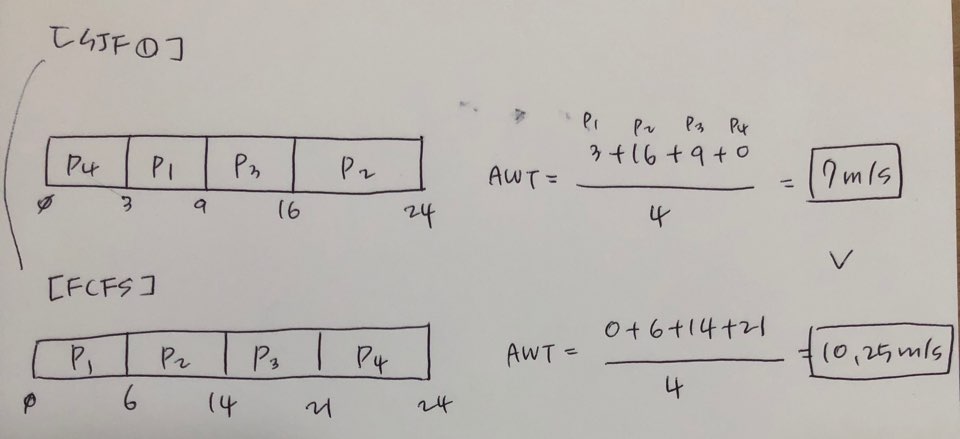
Shortest-Job_First(SJF)
실행시간이 가장 짧은 작업을 가장 먼저 실행함으로써 짧게 끝나는 프로세스를 앞장세워야 전체 대기시간이 줄어들게 함
Example : QWT = (3+16+9+0)/4 = 7msec
ch. 10.25msec(FCFS)
Provably optimal!
대기시간을 줄이는 측면에서는 가장 좋은 방법!
Not realistic, prediction may be needed
비현실적이다. 실제로 이 프로세스가 얼마를 사용할지를 우리는 알수가 없다. 실제 돌려보기 전까지는 전혀 알수가 없다. 그래서 가장 이상적이지만 비현실적이다. 실제로 사용하기에는 예측을 할 수 밖에 없다. 예측하기 위해서는 os가 그동안 cpu를 사용했던 시간들을 다 정리해놓고 예측을 하는 것이긴 이 예측을 하기 위해서는 overhead가 많은것이고 그 만큼의 계산도 많이 들게된다.
Process
Burst Time(CPU 이용시간)
P1
6
P2
8
P3
7
P4
3
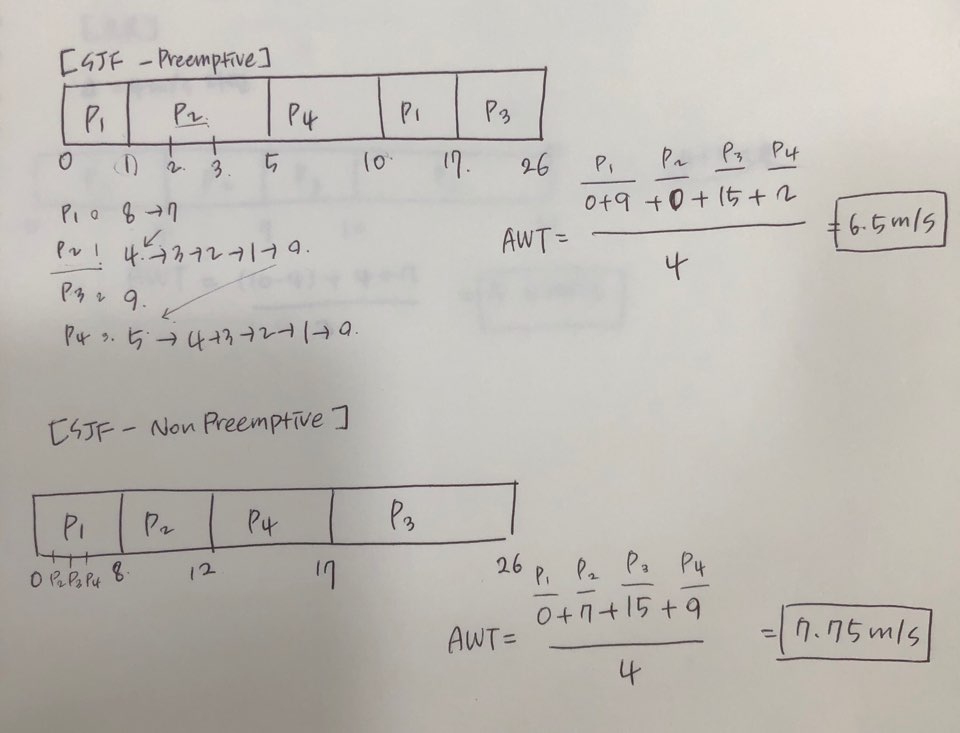
Preemptive or Non-Preemptive
cf. Shortest-Remaining-Time-First(최소잔여시간 우선): 남아있는 시간이 얼마나 짧은가가 우선시가 된다.
Example
Preemptive: AWT =(9+0+15+2)/4 = 6.5msec
Non-Preemptive: 7.75 msec
Process
Arrival-Time
Burst Time(CPU 이용시간)
P1
0
8
P2
1
4
P3
2
9
P4
3
5
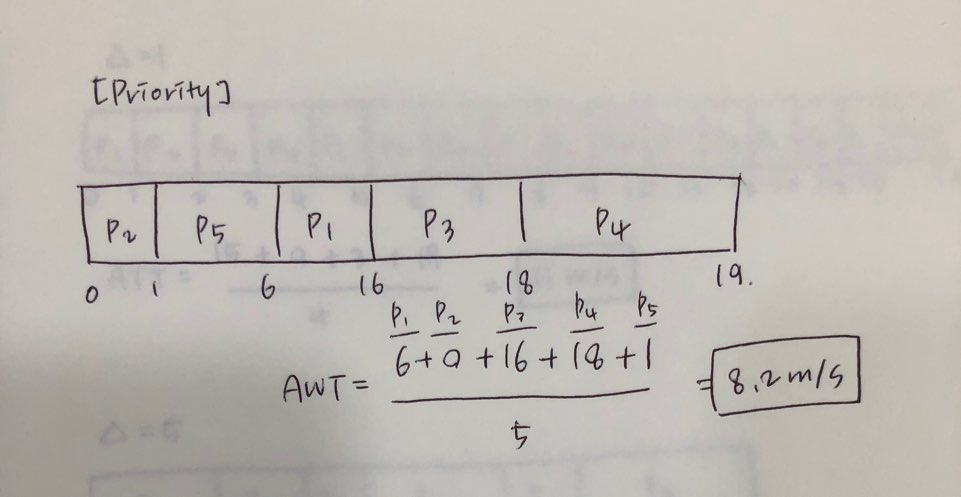
Priority
typically an integer number
Low number represents high priority in general(Unix/Linux)
우선순위, 컴퓨터 프로그램에서는 정수값으로 나타내는데 대부분의 운영체제에서는 숫자가 작을수록 우선순위가 높아진다.
Example
AWT = 8.2 msec
Process
Burst Time(CPU 이용시간)
Priority
P1
10
3
P2
1
1
P3
2
4
P4
1
5
P5
5
2
우선순위는 어떻게 정하는가?
Internal: time limit, memory requirement, i/o to CPU burst…
내부: 짧을수록, 메모리를 적게 사용할수록, io시간이 길고 CPU 사용시간이 적을수록..
External: amount of funds being paid, political factors…
외부: 돈을 많이 낸쪽을 먼저, 정치적인 요소일수록..
Preemptive or Non-Preemptive
둘다 만들 수 있음
Problem
Indefinite blocking: starvation(기아)
한 프로세스가 끝나고 그 다음 우선순위가 작동을 하게 되는데, 이 와중에도 외부에서는 계속해서 작업들이 들어올것이다. 그런데 아무리 오래 기다리고 있다고 하더라고 새로 들어오는 애들이 더 우선순위가 높다면 이전에 있던 애들 중에서도 계속해서 메모리에 올라가지 못하는 애들이 있을 것이다.
Solution: aging
오래 기다릴수록 우선순위를 조금씩 올려주는 것. 레디큐에 오래 머물고 있다면 점진적으로 우선순위를 조금씩 올려줘서 실행을 할 수 있도록 해줌.
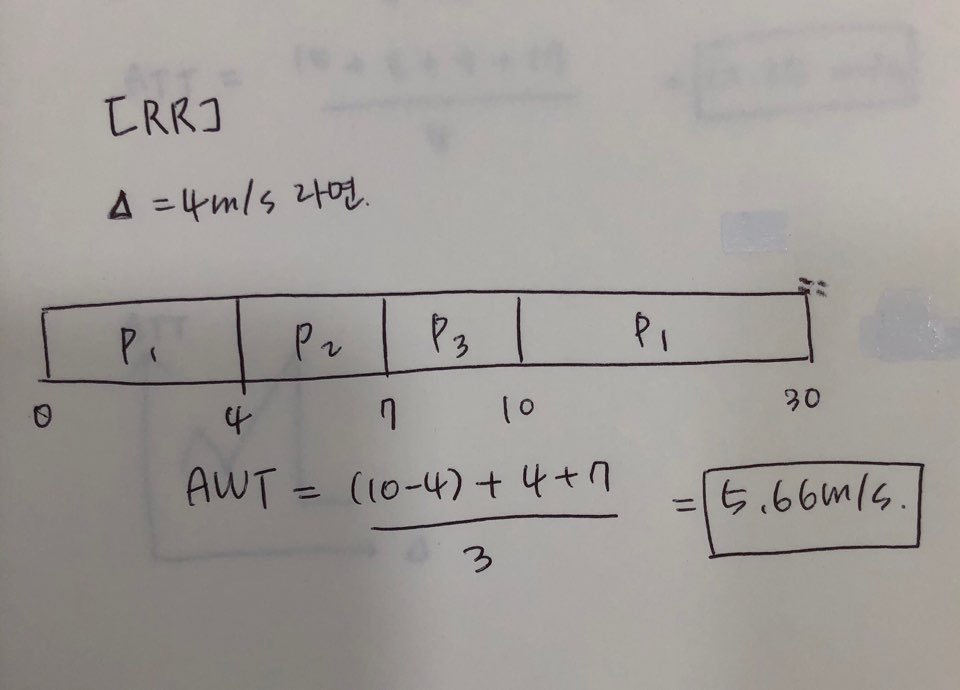
Round-Robin(RR)
빙빙돈다. 빙빙 돌면서 스케줄링한다.
Time-Sharing system(시분할/시공유 시스템): TSS에서 많이 사용하는 방법
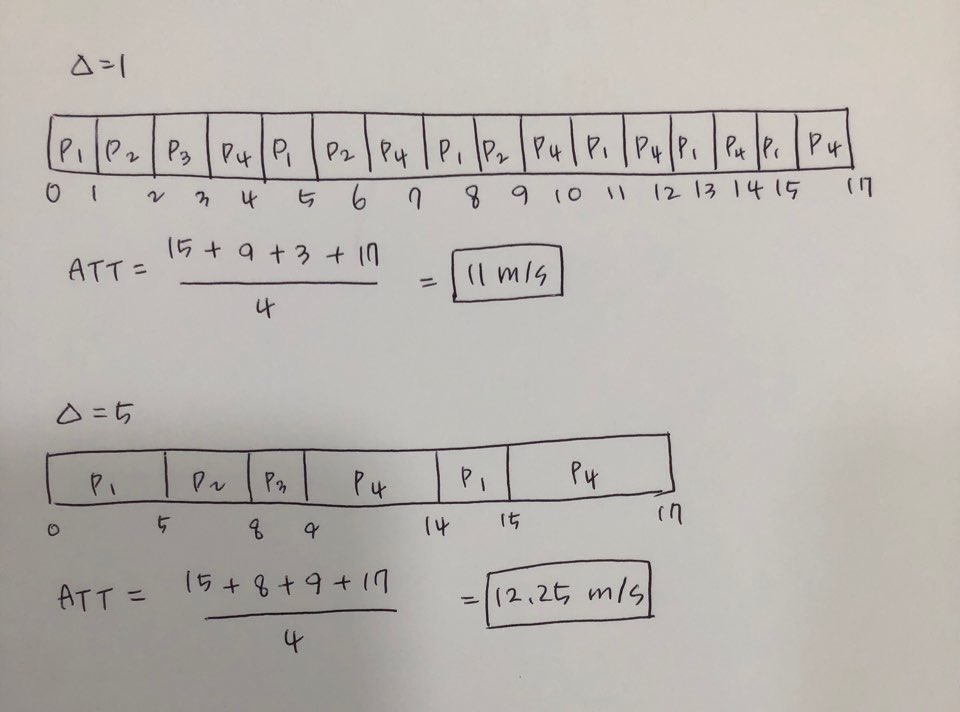
Time quantum(Δ) 시간양자 = time slice (10~100msec) -> 1초동안에 보통 10~100번의 스위칭이 일어난다는 것을 의미!
세 개의 프로세스가 있고 동일한 시간동안 돌아가면서 작업이 이루어지고 이 동일한 시간을 time quantum이라고 한다. 시간양자라고도 한다. 시간의 양. 시간 조각.
Preemptive scheduling: p1이 안끝났다고 하더라도 일정 시간이 지나면 다음 프로세스로 넘어가기 때문에
Example
AWT = 17/3 = 5.66msec
Process
Burst Time(CPU 이용시간)
P1
24
P2
3
P3
3
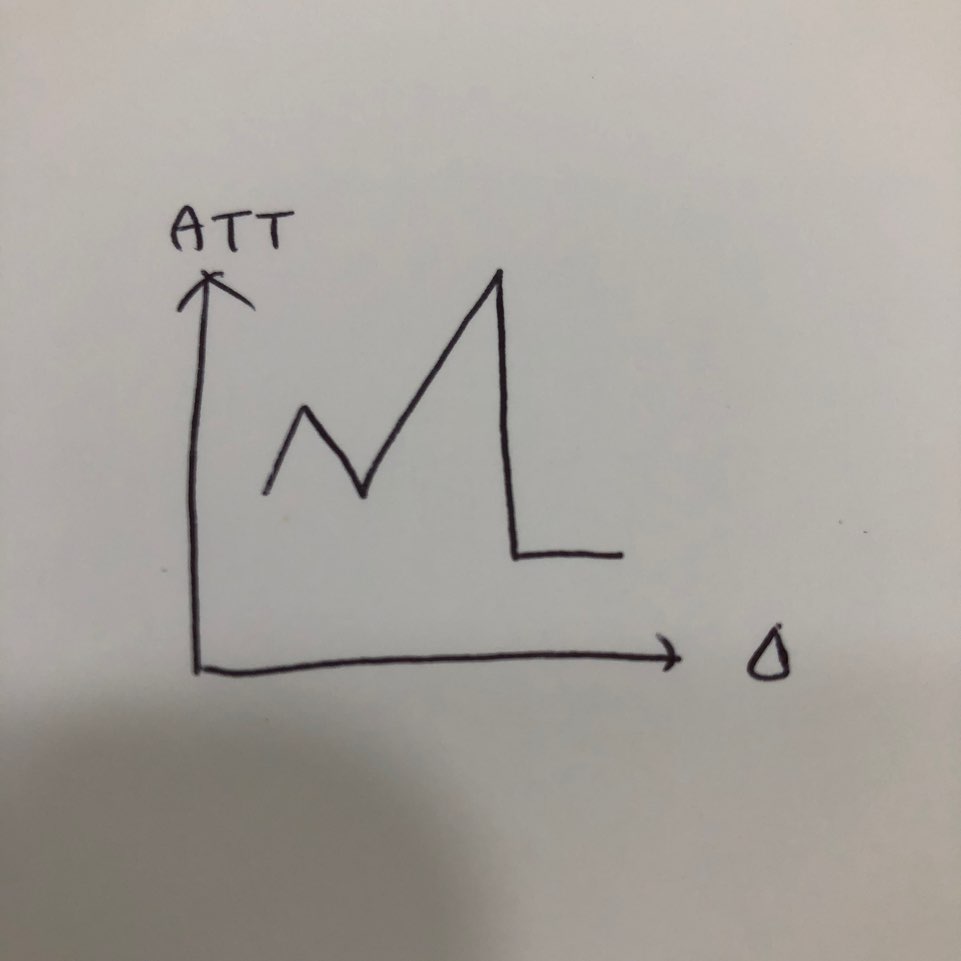
Performance depends on the size of the time quantum: time quantum의 크기에 굉장히 의존적이다.

 지혜의 개발공부로그
지혜의 개발공부로그