지혜의 개발공부로그
지혜의 개발공부로그
디스크 스케줄링(Disk Scheduling) + Disk Scheduling Algorithm
27 Dec 2019 | OS operating system개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
경성대학교 양희재 교수님 수업 영상을 듣고 정리하였습니다.
디스크 스케줄링(Disk Scheduling)
- 디스크 접근시간
- Seek time + retotatinal delay(track이 도는시간) + transfer time
탐색시간(seek time)이 가장 크다 = header를 움직이는 시간
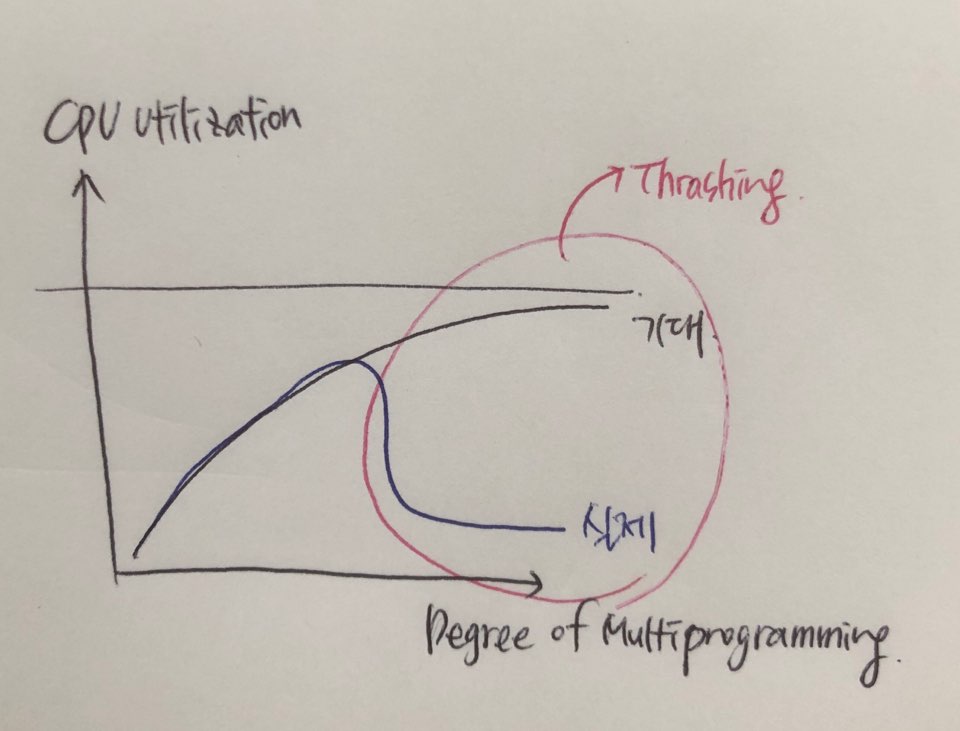
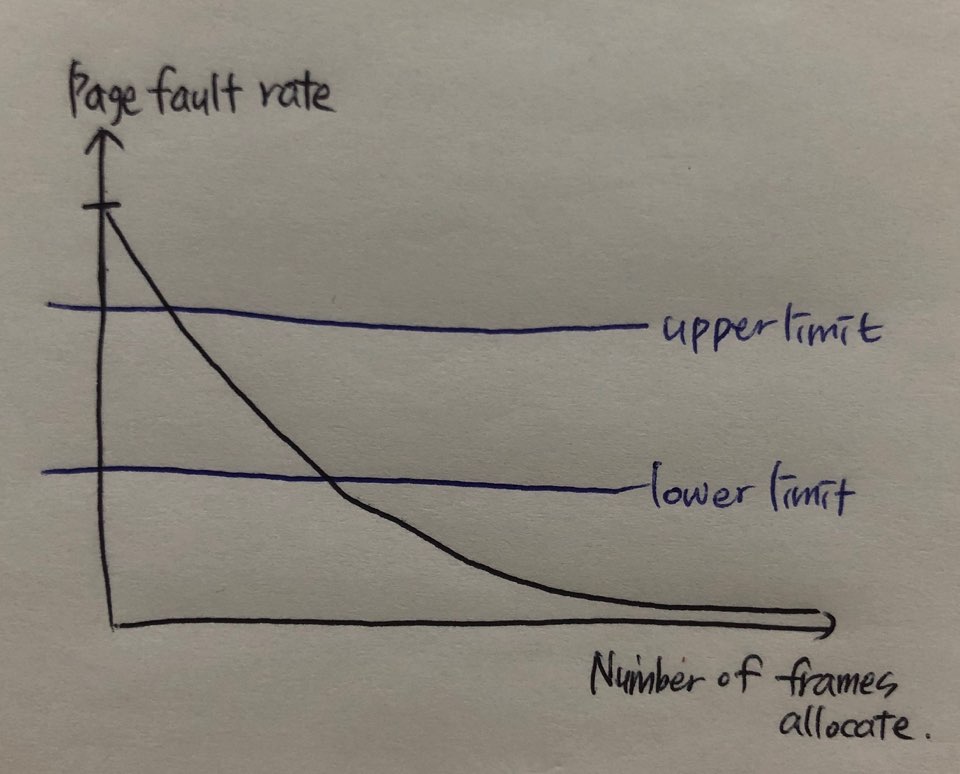
- 다중 프로그래밍 환경(지금 우리의 프로그래밍 환경)
- 디스크 큐(disk queue)에는 많은 요청(request)들이 쌓여있다.
- 요청들을 어떻게 처리하면 탐색시간을 줄일 수 있을까? = 디스크 스케줄링 알고리즘
디스크 스케줄링 알고리즘
- FCFS(First Come First Served)
- Shortest-Seek-Time-First
- Scan Scheduling
- Elevator Algorithm
FCFS(First Come First Served)
가장 먼저온 것을 가장 먼저 실행 -> Simple and fair
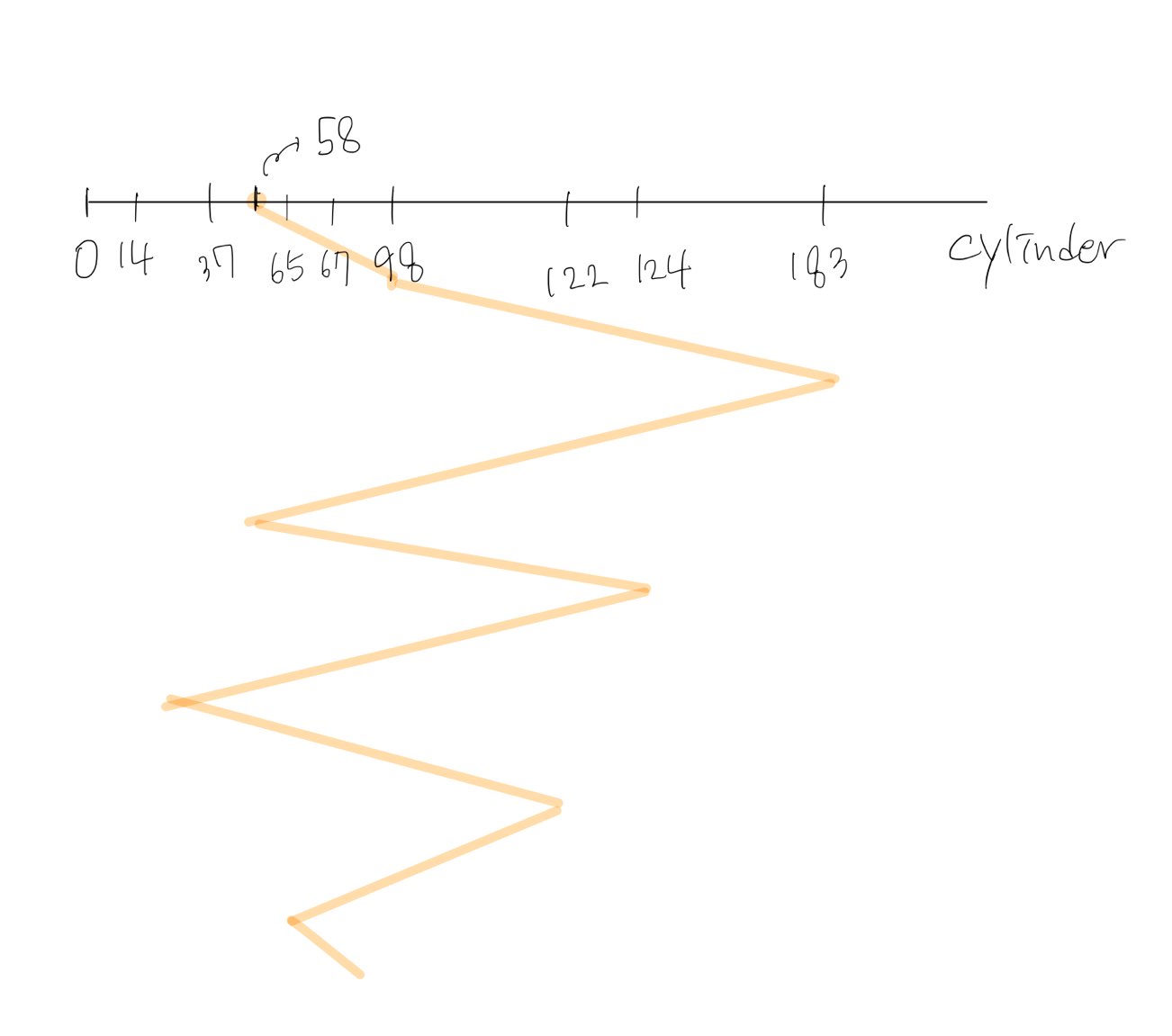
- 예제
- 200cylinder disk, 0 .. 199
- Disk queue: 98 183 37 122 14 124 65 67
- Head is currently ay cylinder 53
- Total head movement = 640 cylinders
- Is FCFS efficient?
Shortest-Seek-Time-First
Select the request with the minimum seek time from the current head position
-> seek time(disk head가 움직이는 시간)이 최소화 되는 것을 가장 먼저 해라
- 예제
- 200cylinder disk, 0 .. 199
- Disk queue: 98 183 37 122 14 124 65 67
- Head is currently ay cylinder 53
- Total head movement = 236 cylinders
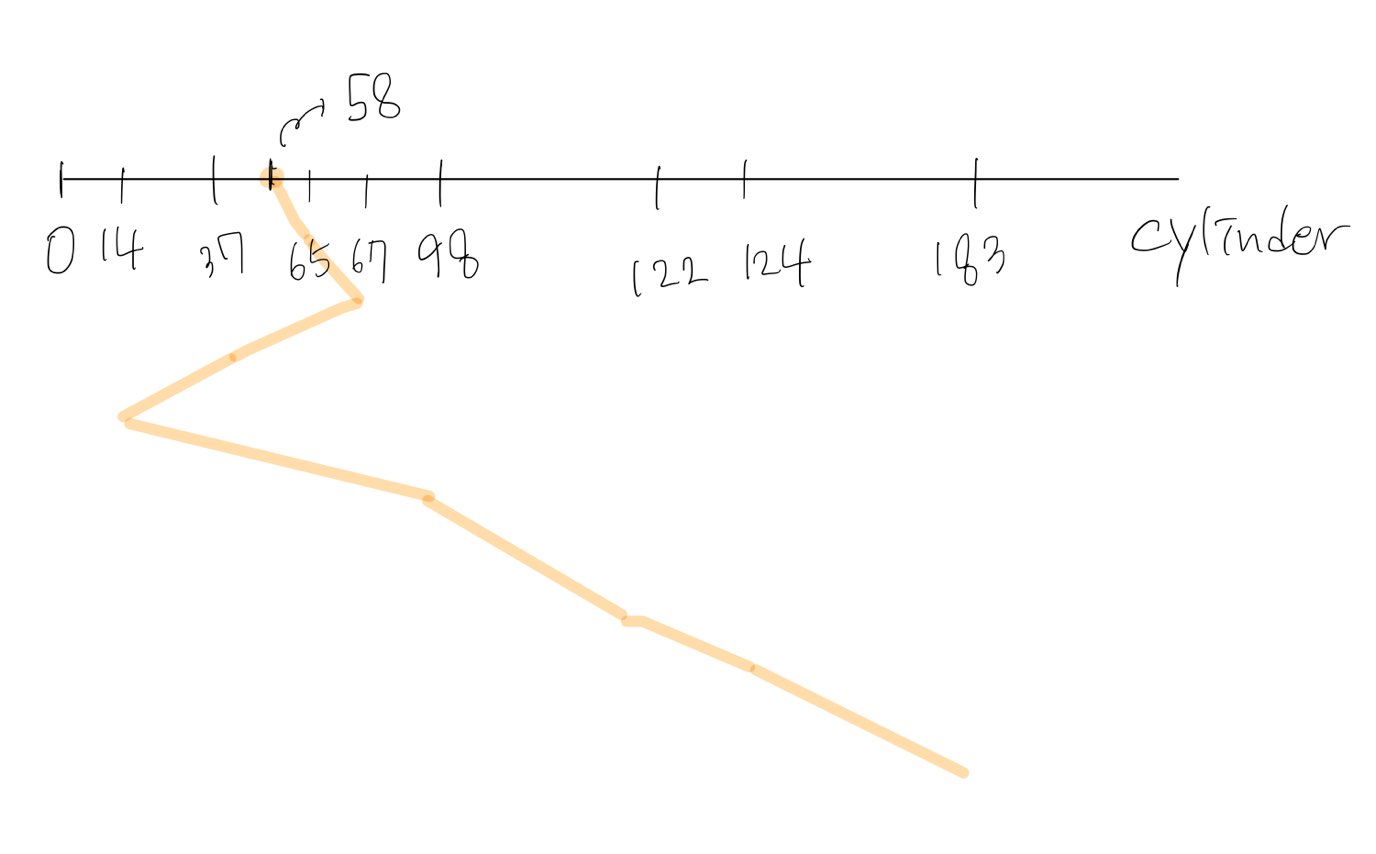
- 문제점
- Starvation
- Is SSTF optimal? No!
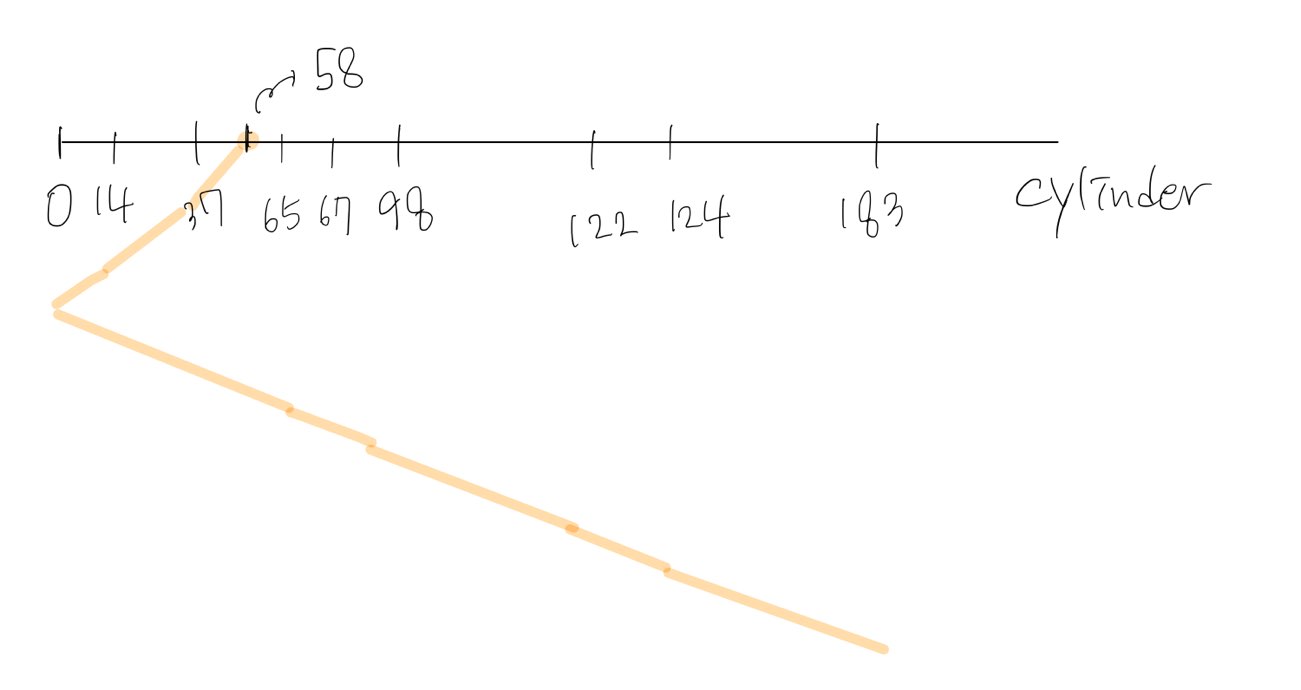
Scan Scheduling
Scan disk: The head continuously scans back and forth across the disk
disk head가 디스크 전체에 걸쳐서 스캔하는것(들어갔다 나갔다가..)
- 예제
- 200cylinder disk, 0 .. 199
- Disk queue: 98 183 37 122 14 124 65 67
- Head is currently ay cylinder 53 (moving toward 0)
- Total head movement = 53 + 183 cylinder(less time)
- 토론
- Assume a uniform distribution of requests for cylinder: request들이 고르게 분포되어있다.
- Circular SCAN is neccessary?
- 일반적으로 request는 하드디스크에 골고루 분포되어있다.
SCAN 알고리즘의 변종
- C-SCAN
- LOOK
- C-LOOK
C-SCAN
Treats the cylinders as a circular list htat wraps around from the final cylinder to the first one
마지막 부분이 첫번째 부분과 연결되어있는 것처럼 생긴 것. 원형모양처럼!
움직인 거리는 더 많을 수 있어도 시간은 훨씬 단축된다!
LOOK
The head goes only as far as the final request in each direction
Look for a request before continuing to meve in a given direction
0을 거치지 않고 바로 turn! 즉 head는 final request까지만 간다!
해당되는 방향으로 계속 갈 것인가를 결정하기 전에 그 이후의 큐가 있는지를 확인하고 움직인다.
C-LOOK
LOOK version of C-SCAN
request의 끝까지만 가는것. 199까지 가는게 아니라 183까지만 간다!
Elevator Algorithm
SCAN알고리즘을 부르는 또다른 호칭
SCAN and variants
- SCAN & C-SCAN
- LOOK & C-LOOK
The head behaves just like an elevator in a building. first servicing all the requests going up, and then reversing to service requests the other way
올리가는 것 쭈욱 서비스하고 내려오면서 또 해결